





The Jasper Blog
Resources for AI in Marketing

How to Create the Non-Commodity Content That Wins AI Search
Google's AI Optimization Guide says non-commodity content wins AI Search. Here's how to actually produce it at scale for AEO and GEO.
July 9, 2026
|
Mason Johnson
July
10
|
Sara Mo Vanacht
Why Generic AI Translation Fails Enterprise Marketing
Leading teams go beyond generic translation tools that strip their brand voice, choosing purpose-built systems that enforce brand voice and quality at scale.
July
8
|
Mason Johnson
What’s New in June 2026
Close the Loop on AI Search
June
29
|
Jessica Kennedy
How To Use the Jasper + monday.com Integration: Close the Gap Between Generated and Shipped
The Jasper monday.com integration exports on-brand content from Jasper directly to new or existing items in monday.com, keeping work moving while reducing manual overhead.
All posts
Join the official Jasper community
Meet marketers, creators, & more sharing tips for generating amazing content 10X faster using AI.
Why Generic AI Translation Fails Enterprise Marketing
Leading teams go beyond generic translation tools that strip their brand voice, choosing purpose-built systems that enforce brand voice and quality at scale.
July 10, 2026
|
Sara Mo Vanacht


How To Use the Jasper + monday.com Integration: Close the Gap Between Generated and Shipped
The Jasper monday.com integration exports on-brand content from Jasper directly to new or existing items in monday.com, keeping work moving while reducing manual overhead.
June 29, 2026
|
Jessica Kennedy
.png)
Jasper + Claude: Bringing Marketing Intelligence Into Your Workflow
How Jasper and Claude work together to bring intelligence, governance, and brand context into marketing workflows at scale.
June 18, 2026
|
Dan Stephen
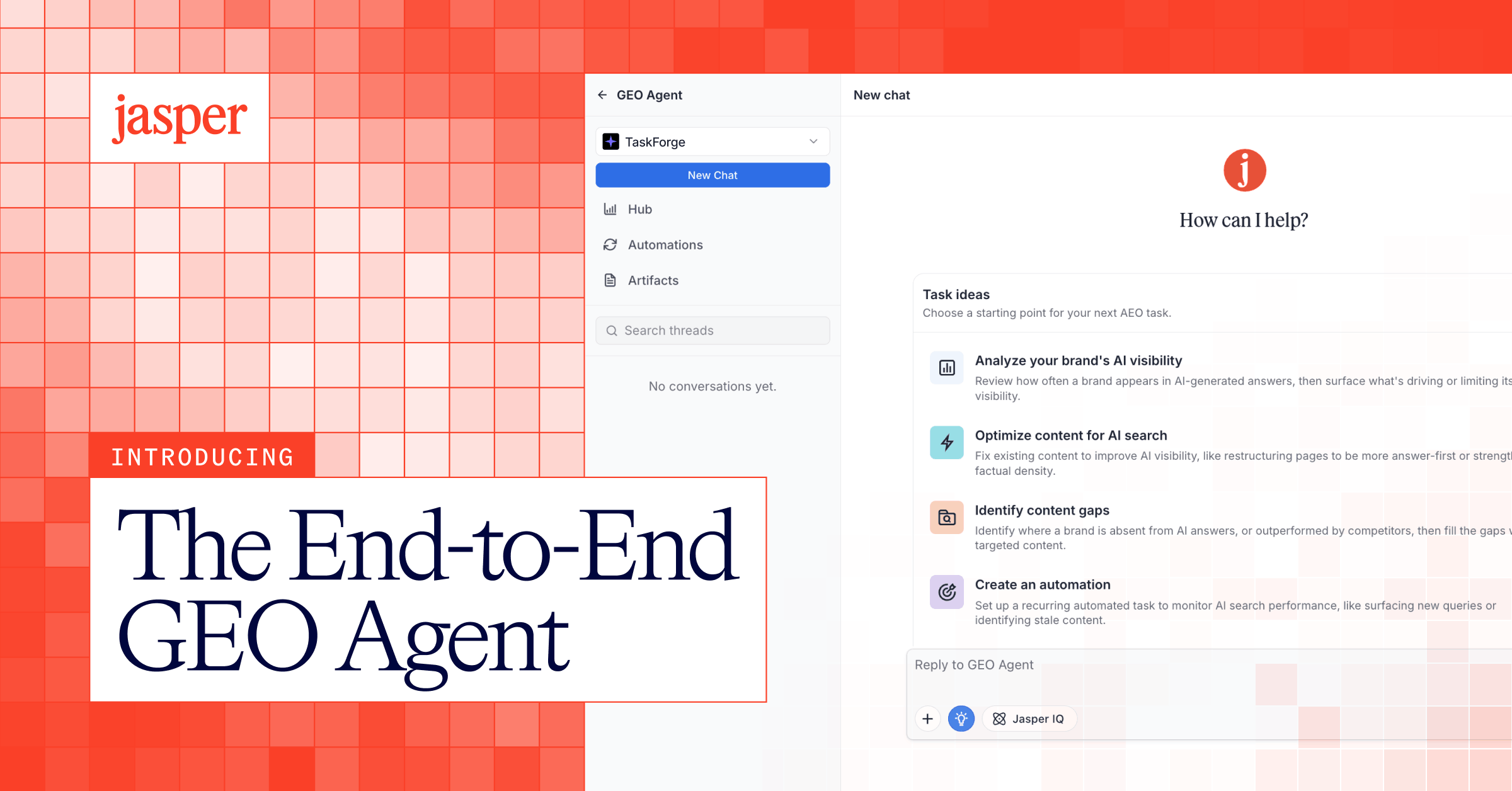
Introducing Jasper GEO Agent and GEO Hub: End-to-End AI Search Optimization
Jasper's end-to-end system for turning AI search visibility into consistent, compounding brand authority.
June 16, 2026
|
Timothy Young

What’s New in May 2026
Put Jasper where your marketing work already happens.
June 10, 2026
|
Mason Johnson

How to Use the Jasper Slack Agent
Create on-brand content without leaving your workflow.
May 27, 2026
|
Jessica Kennedy

Native RGBA Object Removal with Jasper Cleanup v3.0
Cleanup v3.0 delivers real-time, artifact-free object removal for transparent RGBA images via a seamless API integration.
April 28, 2026
|
Damien Henry

Why Brand Consistency is So Important for AI Search Discovery
How to stand out and be the answer in AI search.
April 27, 2026
|
Megan Dubin

How To Use Jasper's Knowledge Base Connectors
Keep your AI agents aligned with your source of truth.
April 22, 2026
|
Jessica Kennedy

Navigating the Shift from Prompting AI to Goal-Driven Agents
As AI agents evolve marketing from task-based assistance to goal-oriented systems, embedding governance at every layer has become mission-critical.
April 21, 2026
|
Bryan Tsao

What is Generative Engine Optimization? GEO vs AEO vs SEO Guide 2026
Learn how generative engine optimization (GEO) and answer engine optimization (AEO) help your content get cited by AI search engines like ChatGPT, Perplexity, and Google AI Overviews.
April 17, 2026
|
Megan Dubin

Digital Marketing’s New Operating Model
Featured leaders from Forrester, Samsara, and Blue Yonder share how AI is changing websites, channel strategy, brand building, and marketing operations.
April 16, 2026
|
Megan Dubin

The #1 Role You Should Hire in 2026 Is a Content Engineer
Content engineering builds the systems that become the foundation for influence in the AI era.
April 1, 2026
|
Loreal Lynch

How To Use the Jasper × Adobe Workfront Integration
Send finished content from Jasper directly into Adobe Workfront, as a link, attached file, or cloud copy, so work moves from creation to approval without stalling in handoffs.
March 31, 2026
|
Jessica Kennedy

Why CMOs and ICs See AI So Differently
AI success looks different at the top and bottom of the org chart. Here’s what you can do to close the gap.
March 5, 2026
|
Megan Dubin

AI is Changing Marketing Roles (and That’s a Good Thing)
Marketing roles are being disrupted by AI, but structured change is leading to clearer ownership and happier teams.
March 4, 2026
|
Megan Dubin

Jasper Named HyperCUBEd Innovation Award Winner in 2026 Tech Innovation CUBEd Awards
The award recognizes companies that lead the market with bold ideas and measurable results.
February 24, 2026
|
Jasper Marketing
.png)
AI Maturity Is the Strongest Predictor of Impact in 2026
The most advanced marketing teams have cracked the code on AI scalability, governance, and ROI measurement.
February 18, 2026
|
Jasper Marketing

What’s New in January 2026
Advancing how marketing teams create, optimize, and deliver content.
February 4, 2026
|
Mason Johnson

AI Content Creation: How It Works, Tools & Best Practices (2026)
AI content creation uses artificial intelligence to plan, write, repurpose, and optimize content at scale. Learn how it works, the best tools, and how teams are using it to move faster without sacrificing quality.
February 2, 2026
|
Jasper Marketing

New Research: The State of AI in Marketing 2026
Trends from 1,400 marketers defining the operational era of AI.
January 28, 2026
|
Jasper Marketing

The Future of B2C Search Isn’t Keywords: Preparing for AI-Driven Discovery in 2026
Discover how B2C brands can win AI search in 2026 with AEO/GEO, trust signals, and structured content for Google, ChatGPT, Perplexity, and Amazon.
January 7, 2026
|
Megan Dubin

3 Ways to Optimize for Search at Scale in Jasper
Learn how Jasper helps enterprise marketing teams optimize for traditional and AI search at scale.
December 22, 2025
|
Mason Johnson

Three Use Cases for Personalization at Scale with Jasper
How Jasper Agents power personalization at scale through outreach, campaigns, and strategic initiatives.
December 22, 2025
|
Megan Dubin

Jasper in Review: How Marketers Used Jasper in 2025
Discover how marketers used Jasper in 2025 with 76M+ generations, millions of campaigns launched, and custom apps transforming daily operations.
December 18, 2025
|
David Pan

Measuring the ROI of Marketing AI
A clear value framework to stop reporting on usage and start measuring outcomes.
December 15, 2025
|
Joyce Yi

Gemini 3 Pro in 24 Hours: Inside Jasper’s LLM-Optimized Architecture
How does Jasper validate new AI models like Gemini 3 Pro in under 24 hours? Inside our rigorous 3-step testing process for enterprise marketing.
December 4, 2025
|
Nick Hough

3 Predictions for AI in Marketing in 2026
In 2026, AI will rewire teams, streamline tooling, and turn content into a competitive engine.
December 2, 2025
|
Loreal Lynch
.png)
Highlights from Jasper Assembly: Scaling Content with Confidence
Discover key insights from Jasper Assembly 2025. Leaders from Sanofi, NetApp, U.S. Bank, and BCG shared AI marketing strategies for scaling content and driving impact.
November 19, 2025
|
Loreal Lynch

Automating Content Pipelines with Jasper Grid
Transform content creation with Jasper Grid’s no-code automation. Scale quality content across channels while maintaining brand consistency.
October 28, 2025
|
Loreal Lynch

Jasper is Now Available on Salesforce AppExchange
Discover how the Jasper and Salesforce Marketing Cloud integration helps enterprise teams generate, personalize, and optimize on-brand content at scale, directly within your existing workflows.
October 22, 2025
|
Jasper Marketing
.png)
Jasper and Braze Integrate to Accelerate On-Brand Campaigns
Jasper and Braze have joined forces to bring AI-powered content creation directly into cross-channel marketing workflows.
October 22, 2025
|
Jasper Marketing

Jasper Powers the Marketing Campaign Creation Behind iHeartMedia's "Cardiac Cowboys" Podcast
Jasper is proud to sponsor "Cardiac Cowboys," a new podcast series from iHeartMedia and OSO Studios. Discover how our AI marketing content automation platform helped connect this incredible story with audiences.
October 14, 2025
|
Jasper Marketing

Steve Kearns Joins Jasper as Head of Customer Evangelism & Community-Led Growth
Jasper welcomes Steve Kearns, an industry leader in AI-powered content strategy and Jasper power user turned advocate for our customer community.
September 30, 2025
|
Jasper

The Most Common AEO and GEO Questions, Answered
An FAQ about adapting your SEO strategy for AI. Get answers to your top questions about answer engine optimization (AEO) and generative engine optimization (GEO).
September 26, 2025
|
Megan Dubin

The Hidden Power of Image APIs in Enterprise Workflows
Discover how Jasper's Images APIs can act as core infrastructure for enterprises, enabling scalability, low latency, and reliability for content workflows.
September 25, 2025
|
Damien Henry

How Jasper Helped Old Dominion Freight Line Scale Expert Content
Old Dominion Freight Line Marketing VP Dick Podiak shares how Jasper has transformed their content scalability, brand trust, and AI search performance.
September 10, 2025
|
Megan Dubin
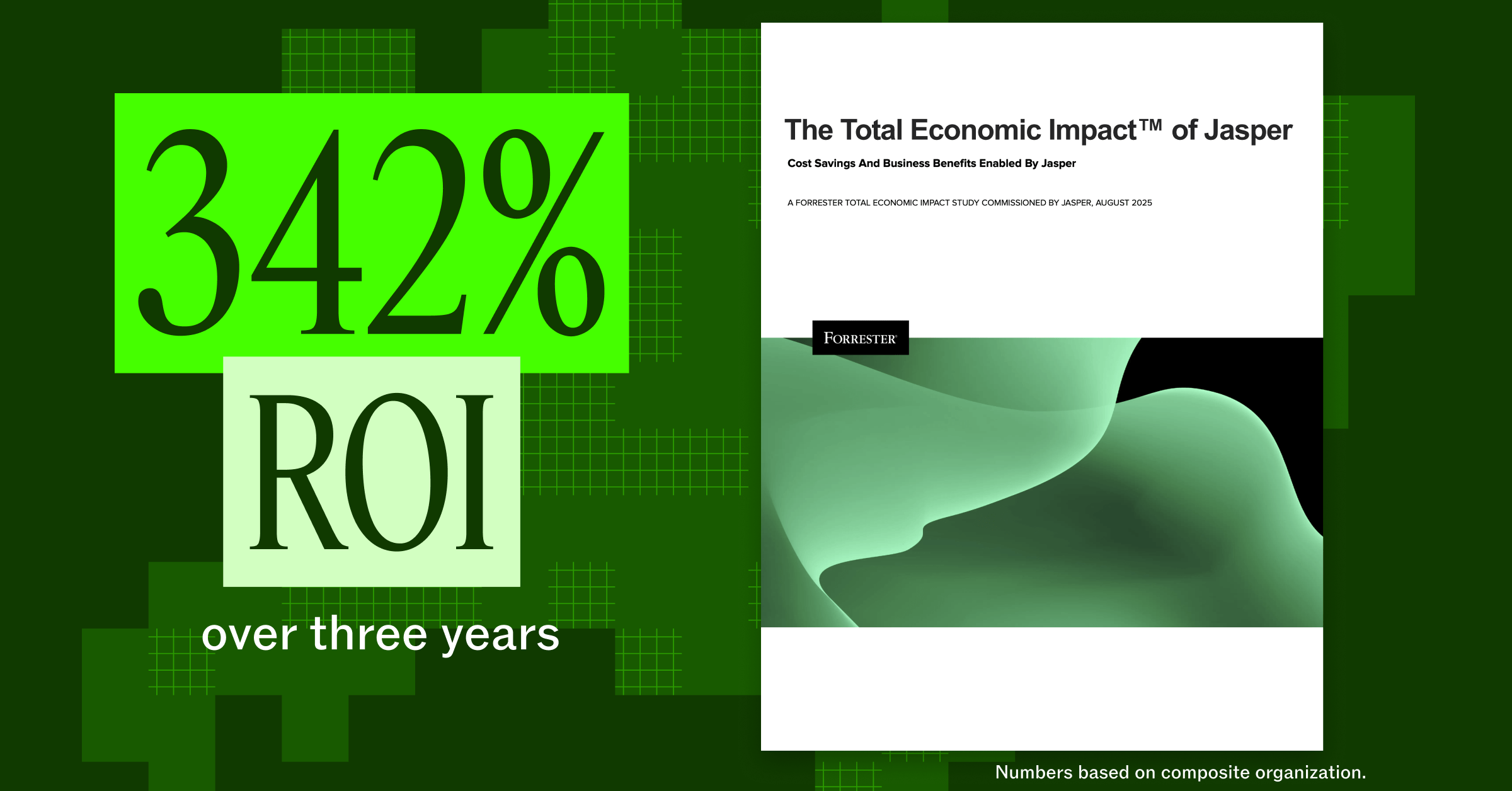
Forrester TEI Study Finds Measurable ROI and Business Impact with Jasper
The Forrester Total Economic Impact™ of Jasper study reveals 342% ROI and $2.2M in annual time savings for Jasper customers.
September 10, 2025
|
Loreal Lynch

The Rise of the Content Engineer: Redefining Marketing in the Next Era
Content engineering is critical for the future of how teams build and scale brand-safe content.
September 2, 2025
|
Loreal Lynch

How I Used Jasper to Create the State of AI in Marketing 2025 Report
From draft to market in record time, thanks to Jasper.
September 2, 2025
|
Esther Chung
.png)
How Leading Retailers Are Using AI to Scale with Precision
See how Anthropologie, Adidas, and Wayfair use AI to scale SEO, content, and campaigns while keeping strategy and brand consistency in focus.
August 26, 2025
|
Megan Dubin

Running Seamless Marketing Launches and Events with Jasper
Discover how Jasper streamlines enterprise launches from ideation to post-launch optimization, driving faster time-to-market and maximum marketing ROI.
August 14, 2025
|
Megan Dubin

How to Quantify Marketing AI Skills Across Your Professional Presence (with Examples)
Marketers need to show not just that they’ve used AI, but that they’ve achieved measurable results. Here’s how.
August 12, 2025
|
Laura Granahan

McKinsey on the Future of Personalization
Eli Stein, Partner at McKinsey, breaks down why true personalization was stuck in “Mad Libs” mode, how AI shifts the paradigm, and what it takes to build full‑journey personalization at scale.
August 4, 2025
|
Megan Dubin

What Is ChatGPT? Horizontal vs. Purpose-Built AI
What is ChatGPT and how does it differ from purpose-built AI? Learn the key distinctions for enterprise marketers focused on security, brand voice, and ROI.
August 1, 2025
|
Jasper Marketing
Jasper Pixel-Perfect Imagery: Driving Advantage for Enterprise Marketers
Learn how Jasper delivers scalability and precision in visual content generation not achievable with generic AI alternatives.
July 31, 2025
|
Damien Henry

LinkedIn's Steve Kearns on AI, Brand, and the B2B Marketer’s Moment
Steve Kearns, Global Head of Content at LinkedIn Ads, shares how AI has brought human connection even further to the forefront for B2B marketing.
July 28, 2025
|
Esther Chung

Legal Rulings on AI Fair Use and What it Means for Jasper
Takeaways from recent court decisions on AI training and usage as they relate to implications for Jasper in the future.
July 18, 2025
|
Jasper Marketing

6 Kinds of AI Writers’ Tools for Marketers in 2026
Discover six types of AI writers' tools that optimize the content lifecycle and why a central content automation platform is the best way to adopt them.
July 15, 2025
|
Jasper Marketing

How to Accelerate Content with AI Reword Generators
Learn how AI rewording generator tools reduce friction in the writing process and power more seamless marketing content creation.
July 15, 2025
|
Jasper Marketing

Scaling AI for the Enterprise: How Marketing Leaders Drive Impact
High-performing marketing teams are scaling AI with structure and strategy. Learn how CMOs can lead the way to drive organization-wide impact.
July 1, 2025
|
Megan Dubin

How AI is Reshaping SEO for the Next Era of Search
Explore how AI capabilities are transforming online search, how it's impacting the user experience, and actionable ways for marketers to keep pace with the change.
June 26, 2025
|
Megan Dubin

How to Create Personal Bios for Content Authors That Support SEO and GEO
Discover how personal bios for content authors enhance SEO by building trust and showcasing expertise.
June 24, 2025
|
Megan Dubin

Reflections from Cannes: Why Brand and People Still Matter Most in the Era of AI
At Cannes Lions 2025, one truth stood out: brand, trust, and authenticity are making a powerful comeback.
June 24, 2025
|
Loreal Lynch

5 Video Script Templates for Impactful Enterprise Marketing
Discover 5 video script templates to create impactful content that boosts engagement.
June 23, 2025
|
Jasper Marketing

Building a Robust AI-driven Content Strategy for Enterprise Success
Discover how enterprises can use AI for content marketing, market research, and automation to boost ROI and efficiency.
June 23, 2025
|
Jasper Marketing

Interactive Tool: Benchmark Your AI in Marketing Strategy
Discover your marketing team's AI maturity. Benchmark your strategy, compare with peers, and uncover gaps with an interactive tool.
June 17, 2025
|
Megan Dubin

How to Use AI to Write Blog Introductions That Hook Readers
Introductions can make or break a blog post, but they’re not always easy to write. Here's how to approach blog intros with AI.
June 16, 2025
|
Jasper Marketing

Introducing the New Jasper: The First Multi-Agent Platform Built for Marketers
Discover the new Jasper AI experience, built for enterprise marketers to scale content and strategy with precision and true-to-brand authenticity.
June 10, 2025
|
Timothy Young

Why the Traditional Content Lifecycle No Longer Works
Learn why traditional content workflows break down, and how AI can rewire the marketing lifecycle to unlock scale, consistency, and ROI.
June 10, 2025
|
Megan Dubin

The State of AI in Financial Services Marketing 2025
Financial services marketing teams are ahead in AI maturity. Learn how they can scale responsibly and innovatively to maintain their competitive edge.
June 3, 2025
|
Jasper Marketing

How AI Agents Are Transforming Marketing Workflows
AI agents move beyond task automation to deliver real-time optimization, brand governance, and marketing outcomes across channels.
June 1, 2025
|
Jasper Marketing

The State of AI in Life Sciences Marketing 2025
Learn where life sciences marketing measures up in AI adoption and how domain-specific tools can help teams drive results.
May 29, 2025
|
Jasper Marketing
.png)
Latent Bridge Matching: Jasper AI’s Game-Changing Approach to Image Translation
Discover how latent bridge matching, pioneered by the Jasper research team, transforms image-to-image translation with unmatched speed, quality, and efficiency.
May 28, 2025
|
Jasper

Why Domain-Specific AI is Key to Increasing Content ROI
Discover how marketers can use purpose-built AI (including an example with Jasper) to create high-quality, on-brand content at scale.
May 21, 2025
|
Tom Newton

Why Context is the Ultimate Differentiator for AI in Marketing
Context is the key to making AI work in marketing. Here’s why generic tools fall short and contextual AI drives better results.
May 20, 2025
|
Loreal Lynch

Introducing Audiences: Unlocking Campaigns That Truly Resonate
Discover how Audiences can transform marketing campaigns with dynamic, actionable audience insights.
May 14, 2025
|
Bryan Tsao

Jasper Joins NYSE LaunchPad and Launches Inaugural Customer Advisory Board
Discover how Jasper’s CAB and inclusion in the NYSE LaunchPad program are driving innovation for enterprise marketers.
May 7, 2025
|
Jasper

AI Trends Shaping Tech Marketing in 2025
Technology is the clear industry leader in AI adoption, but surprising gaps still remain to reach AI’s full potential.
April 29, 2025
|
Jasper Marketing

The 7 Traits of Marketing Organizations Leading in AI Maturity
Discover the 7 traits of marketing teams leading in AI—plus a roadmap to help your team unlock its full potential.
April 20, 2025
|
Jasper Marketing

The State of AI in Retail Marketing 2025
Retail is ahead of the AI adoption curve in 2025, but gaps and opportunities remain. Get exclusive insights for retailers from Jasper’s latest research.
April 8, 2025
|
Jasper Marketing

The HERDS Framework: Mobilizing Change Leaders to Scale AI in Marketing
Learn how to drive adoption, engage stakeholders, and overcome resistance with this AI change management framework.
March 30, 2025
|
Jessica Hreha

The Future of Retail Visuals with AI: A Conversation with Wayfair’s Bryan Godwin
Wayfair’s Director of AI & Visual Media on how AI is transforming retail visual content—enhancing personalization, brand consistency, and efficiency at scale
February 6, 2025
|
Loreal Lynch

AI, Light, and Shadow: Jasper's New Research Powers More Realistic Imagery
Jasper Research Lab’s new shadow generation research and model enable brands to create more photorealistic images with enhanced realism and depth.
February 4, 2025
|
Onur Tasar

How to Redefine Your ABM Playbook Using AI
Explore key takeaways from our recent webinar on how AI can transform ABM strategies with workflow automation, personalization at scale, and more.
January 6, 2025
|
Jasper Marketing

Jasper Named a 2025 NRF Innovator at Retail’s Big Show
The Innovators Showcase at NRF 2025: Retail’s Big Show recognizes the top 50 tech leaders shaping the future of retail.
December 11, 2024
|
Jasper Marketing

How AI Workflows are Redefining Enterprise Marketing - Insights from McKinsey and Jasper
Discover AI's impact on enterprise marketing. Learn about transformation stages, AI workflows, and scaling strategies for growth and ROI.
December 3, 2024
|
Jasper Marketing
How to Automate Your Workflows With AI
AI workflow automation is becoming one of the main levers organizations can modernize their operations. Here's how.
November 24, 2024
|
Jasper Marketing

.png){kind=link}






